Once upon a migration I would use sp_help_revlogin to migrate logins and remap the SQL server logins using sp_change_users_login. During some recent migration work I realised that SQL Server Management Studio could do most of the work of sp_help_revlogin. I still needed to use sp_change_users_login – but I came across a couple of other tips to solve a couple of issues.
Note: The terminology can be a bit ambiguous and confusing here. When I talk about logins I mean all security principals that can be used to access the SQL Server instance, either Windows or SQL principals. When I talk about SQL server logins – I mean logins that use SQL authentication, as opposed to logins that use Windows authentication.
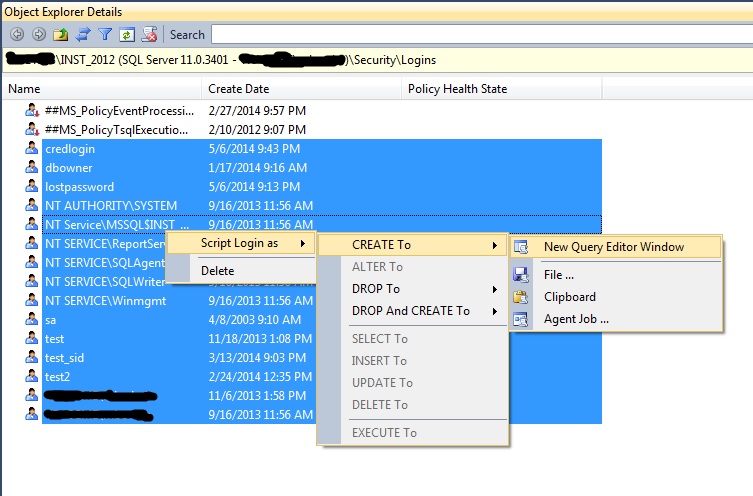
SSMS: To script out all logins from a SQL server instance simply select the logins node in the security node of object explorer and open the object explorer details window ([F7]). This window allows you to shift click to multi-select logins and right click to script out as desired. One caveat here is that the script to create the SQL server logins will generate random passwords – these need to be replaced with the correct passwords.

Mapping SQL logins: Logins based on Windows AD accounts will remap automatically across SQL instances in the same domain because the SIDs are the same, set by Windows as opposed to SQL Server. But SQL server logins will be assigned a random SID when created. Because the mapping between a SQL server login and a database user is based on SIDs the Windows logins will remap, but the SQL server logins will not. The well known procedure sp_change_users_login can be run in a database context to identify these ‘orphaned’ logins and remap them.
Creating SQL logins with specific SIDs: I had a situation recently where I migrated a data warehouse server. Production databases were restored to the server each night, data scrubbed and then set to read-only. I needed a login on the SQL Server to be mapped to a database user so that queries could be run against the warehouse. In this case the login I had was a SQL server login – so when I migrated instances the login SID did not match the SID of the user in the production databases. Sp_change_users_login won’t work on a read-only database because the metadata can’t be written. My options where to remap the database users to the login after every restore but before setting the database to read-only or to create the login on the server with a SID matching the SID on the production boxes. It turns out that a SQL login can be created with a specific SID. The following query can be run against the source server master database and will produce create scripts for all logins with explicit creation of SIDs – which can be run as required on the destination server.
SELECT
'create login [' + p.name + '] '
+ case
when p.type in('U','G') then 'from windows '
else ''
end
+ 'with '
+ case
when p.type = 'S' then 'password = '
+ master.sys.fn_varbintohexstr(l.password_hash)
+ ' hashed, '
+ 'sid = '
+ master.sys.fn_varbintohexstr(l.sid)
+ ', check_expiration = '
+ case
when l.is_expiration_checked > 0 then 'ON, '
else 'OFF, '
end
+ 'check_policy = '
+ case
when l.is_policy_checked > 0 then 'ON, '
else 'OFF, '
end
else ''
end
+ 'default_database = ['
+ p.default_database_name
+ case
when len(p.default_language_name) > 0 then '], default_language = ['
+ p.default_language_name
+ ']'
else ']'
end
FROM sys.server_principals p
LEFT JOIN sys.sql_logins l
ON p.principal_id = l.principal_id
WHERE p.type in('S','U','G')
Forgotten passwords: Another issue I came across in a recent migration was passwords that had fallen through the cracks and been forgotten. After spending some fruitless hours trying to get hashcat to work properly – and failing – I revisited the query above. Turns out I didn’t need to recover passwords – I could recreate the logins using the password_hash. To convince myself of this I create a login to test with.
USE [master]
GO
CREATE LOGIN [lostpassword]
WITH PASSWORD=N'I_f0rg0t!'
, DEFAULT_DATABASE=[master]
, CHECK_EXPIRATION=OFF
, CHECK_POLICY=OFF
GO
Run the login script from above which for [lostpassword] gives:
create login [lostpassword]
with password = 0x02002c4b16cfbc80f3d07ab3d67042262a87370fc7f0a6300badcddd999ec304c9e69137d5f90b307a230330a25e41ca3e9d3a2664d2782aafe1611608afedfabf67b44ef22e hashed
, sid = 0xed5cd87e54a8bc43b7ff9435f052e2cd
, check_expiration = OFF
, check_policy = OFF
, default_database = [master]
, default_language = [us_english]
Drop the login that I originally created.
DROP LOGIN [lostpassword]
And recreate the login using the generated script.
create login [lostpassword]
with password = 0x02002c4b16cfbc80f3d07ab3d67042262a87370fc7f0a6300badcddd999ec304c9e69137d5f90b307a230330a25e41ca3e9d3a2664d2782aafe1611608afedfabf67b44ef22e hashed
, sid = 0xed5cd87e54a8bc43b7ff9435f052e2cd
, check_expiration = OFF
, check_policy = OFF
, default_database = [master]
, default_language = [us_english]
And confirm that the recreated login’s password matches the original.
SELECT name FROM sys.sql_logins
WHERE PWDCOMPARE('I_f0rg0t!', password_hash) = 1 ;
Which it does:

Another tool for the migration toolkit.










